I databas modellering skapar man en modell över heladatabasen med dess objekt, attribut och relationer.
Datamodellering består av tre stycken modeller.
1. Konceptuell modell - ska återspegla verksamheten / verkligheten
2. Logisk modell - En teoretisk modell som bygger på konceptuella modellen.
3. Fysisk modell - En praktisk modell som är anpassad till den verkliga databashanteraren.
Konceptuell modell.
- Identifiera objekt som är viktiga för verksamheten. (Kund, Artiklar, Faktura)
- Identifiera Relationerna (Se bilden)
- Identifiera Attributen tex. Fält, egenskaper (Telefonnummer, namn, address, antal, pris osv)
- Identifiera Nycklar (Primary key, alla tabeller behöver en unik nyckel för varje rad)
- Tabellexempel med data (kundid=1, namn=Pelle Pellsson,Adress=Kaaatan2) se även till att det hänger ihop genom Primary key och Foreign key.

0 - Frivillig (En kund behöver inte ha en telefon)Datamodellering består av tre stycken modeller.
1. Konceptuell modell - ska återspegla verksamheten / verkligheten
2. Logisk modell - En teoretisk modell som bygger på konceptuella modellen.
3. Fysisk modell - En praktisk modell som är anpassad till den verkliga databashanteraren.
Konceptuell modell.
- Identifiera objekt som är viktiga för verksamheten. (Kund, Artiklar, Faktura)
- Identifiera Relationerna (Se bilden)
- Identifiera Attributen tex. Fält, egenskaper (Telefonnummer, namn, address, antal, pris osv)
- Identifiera Nycklar (Primary key, alla tabeller behöver en unik nyckel för varje rad)
- Tabellexempel med data (kundid=1, namn=Pelle Pellsson,Adress=Kaaatan2) se även till att det hänger ihop genom Primary key och Foreign key.

1 - Tvingande (En telefon måste gå till en kund)
B - Beroende (Samma karaktär som tvingande)

0. En kund behöver inte ha en telefon.
1. En telefon måste ha en kund.
B. Ett underliggande objekt ifrån kund som kan innehålla Kontaktpersoner.
Atomära fält = fält med endast en sammanhängande information
Delbart fält = fält som innehåller kanske för och efternamn
Logisk Modell
- Objektifiering: rita om alla relationsobjekt till objekt och skapa attribut i dem (vänd på gafflarna)
- Normalisering: Gå igenom normaliserings reglerna.
Normaliserings Regler:
nr1. alla objekt ska ha en unik nyckel (Primary key)
nr2. Varje egenskap ska bero på hela nyckeln
nr3. En egenskap får endast bero på nyckeln. Det får inte förekomma några inbördes relationer.
nr4. En egenskap får endast finnas en gång i en tabell annars växer tabellen i sidled. (tex telefonnummer ska endast finnas i en kolumn. [Kundid][telefonnummer][telefontyp])
Fysisk Modell
- Generalisering Ta bort tex. telefon och döp den till kontakt så kan man ha epost, telefon, fax och allt möjligt i den. skapa sedan en relation med en typ tabell så man vet vilken typ det är.
- Denormalisering (se om vissa normaliseringar kan tas bort, kräver bra argument) behåll sådana saker som man endast kan välja vissa av. tex Moms objekt.
- Optimering radvis/kolumnvis delegering/sammanslagning
- Indexering (se vilka tabeller som ska indexeras för att göra sökning snabbare)
- Tabellprecisering (Bestäm datatyp, Namn=text(antal tecken), Telefon=text/nummer?(antal?))
Optimering
Optimera data genom att kanske skapa två tabeller, KundA och KundB. Kund B kanske innehåller data som inte används så ofta. Eller om tabellen blir väldigt bred med mycke information. Man kan även separera publik data och säkerhetskänslig data.
Man kan även dela upp tabeller i Aktuell samt gammal info. (En tabell per år)
Fördelar: Korta tabeller ger snabb tillgänglighet, lätt att organisera arkivering av gammal data
nackdelar: Måste byta tabeller, svårare att göra statistik över flera tabeller.
Indexering
-Oindexerat (heap) långsamt
- indexerat (sorted/hash) snabbt
Vilka tabeller ska indexeras? Genom att indexera tabeller blir sökningen snabbare. Om man indexerar för många tabeller blir det segt så det gäller att välja vilka tabeller som ska indexeras.
Index-Sekventiell access metod
indexera tex namn och få fram en lista på namn och med hjälp av ID som hör ihop med namn går det snabbt att hitta till rätt post.
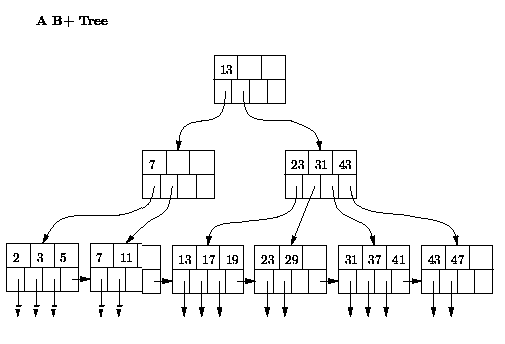
Balanserat träd (B tree)
Objekt delas upp i små segment som ett träd och snabbar upp sökning för att den slipper gå igenom hela databaslistan för att hitta rätt rad. Exempel på Btree
Sammansatt PK/FK
man kan sätta in Primary Key och Froeign key i en och samma tabell för att få snabbare sökning.
Tabellprecisering
vilka olika datatyper ska man använda?
Namn = varchar(50)
Kundid = Int
Organisationsnummer = C(11)
ort = Varchar
Postnummer = Int
Betaldatum = Date
Antal = SmallInt
MomsID = Smalint
Moms = Decimal (2,2)

{kind=link}
Inga kommentarer:
Skicka en kommentar